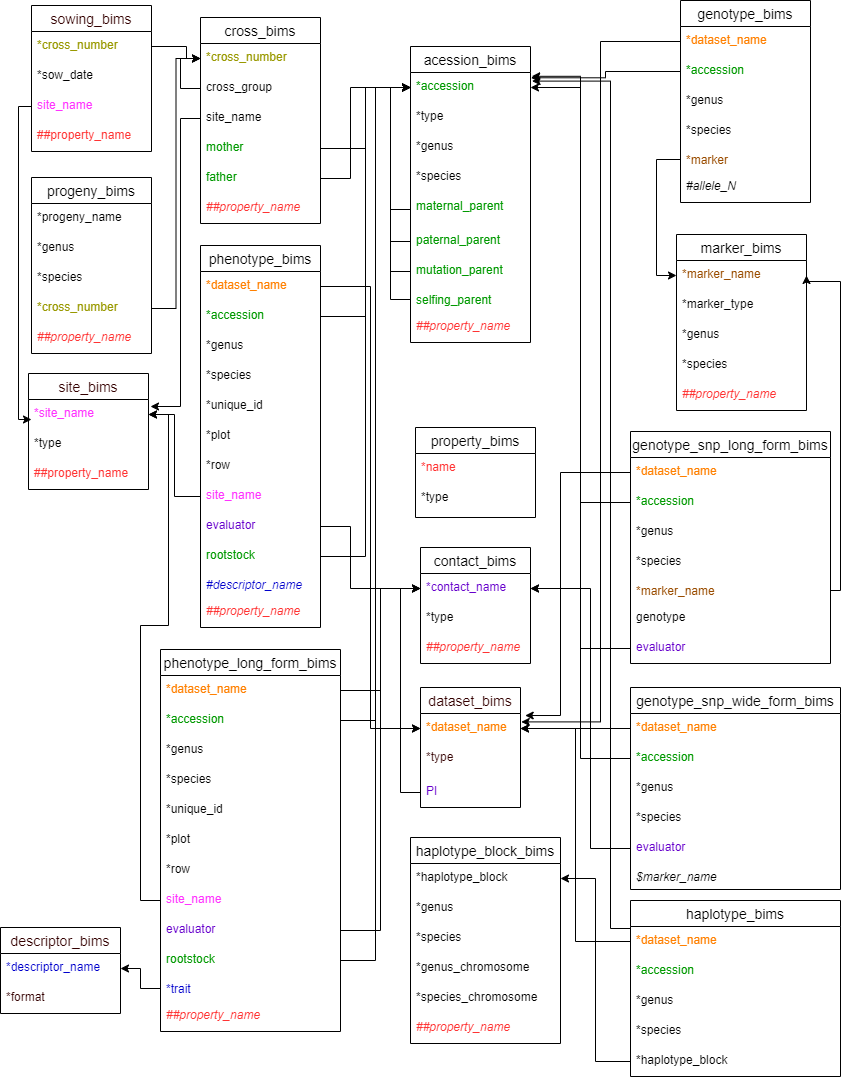
BIMS template diagram
Data in some of the columns refer to data in other templates or data already entered to BIMS so the data needs to match exactly. For example, phenotype_bims has the dataset_name column and the data entry should match the data in the dataset_name column of the dataset_bims. Once an entry in the dataset_bims is loaded to BIMS or the dataset names are entered using the BIMS interface, users can enter it in phenotype_bims without entering the same entry again in dataset_bims. The data types that need to be entered to BIMS either using the template or the BIMS interface before being used in other templates include dataset, accession, trait descriptor, and site. Contact, custom property, marker, and haplotype block data can also be used in other templates and their detailed data need to be entered to BIMS using contact_bims, property_bims, marker_bims, and haplotype_bims. Entries in property_bims, descriptor_bims, and marker_bims can be used as column headings in some of the other templates and they need to have a special prefix when used as headings; # for descriptor_name, ## for property_name, and $ for marker_name.
Figure below shows all the templates available in BIMS with column names that are either required or have relationships with other columns. Matching column names have the same color and they are connected by an arrow. Arrows between property_name columns were omitted to make the diagram less busy. Progeny_name in progeny_bims can also be used, as well as accession in accession_bims, in entering accession information in other templates. However the arrows to the progeny_name in progeny_bims were skipped to make the diagram simpler. Matching columns in various templates do not always have the same column headings. For example, the evaluator column in phenotype_bims refers to a contact_name in contact_bims.